
Nvidia has announced a new open source software package aimed at drastically improving the performance of large language model inference on its latest GPU accelerators, H100.
Inference speed refers to the rate at which a trained machine learning model can process input data and generate predictions or decisions based on that data. It measures how quickly the model can make inferences or draw conclusions from the information it has learned during its training phase.
Imagine a user asking ChatGPT, “How can I reset my Google password?” They expect a quick reply. Efficient inference speed ensures the chatbot swiftly provides accurate instructions, enhancing the user experience, and enabling the chatbot to handle multiple users and increased demand effectively.
The new open-source software by Nvidia, TensorRT-LLM, that is set to release in the next few weeks for Ampere Lovelace, and Hopper GPUs, can double the inference speed on H100, the chipmaker has claimed in a statement. The company has been working with leading technology firms, including Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML, OctoML, Tabnine, and Together AI, to accelerate and optimize LLM inference, and TensorRT-LLM has been built as a result of these efforts.
TensorRT-LLM comes equipped with fully optimized, plug-and-play versions of numerous large language models commonly employed in today’s production environments. These encompass Meta Llama 2, OpenAI GPT-2, GPT-3, Falcon, Mosaic MPT, BLOOM, and a variety of others, all of which can be seamlessly integrated using the user-friendly TensorRT-LLM Python API, making it easier to deploy the models.
The software incorporates techniques like in-flight batching and half-precision numerical formats to maximize utilization of Nvidia’s H100 GPUs based on the Hopper architecture.
In-flight batching allows unfinished model executions to be evicted from batches, making room for new inference tasks to begin running without waiting. This helps address the dynamic nature of language model workloads that can vary widely in response lengths. The software also implements 8-bit floating point (FP8) quantization to reduce model sizes in memory without degrading accuracy.
Benchmark results released by Nvidia show impressive gains over previous generations. For smaller models like OpenAI’s 6 billion parameter GPT-J, TensorRT-LLM delivered up to 8 times higher throughput on H100s compared to an Nvidia A100 alone. Even for gigantic models on the cutting edge, such as Meta’s 70 billion parameter Llama, speedups were a substantial 4.6 times using H100s with the new software.

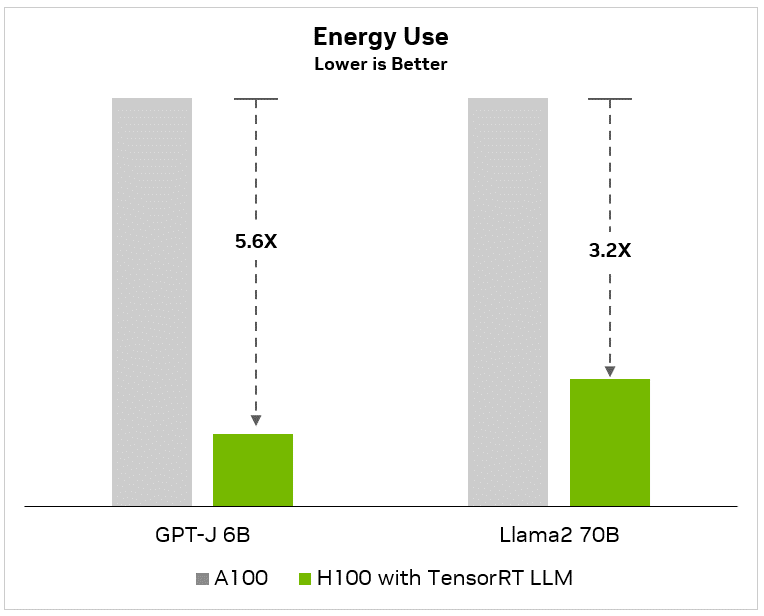
Perhaps more significantly for large-scale AI adopters, Nvidia estimates these performance boosts translate directly into 3 to 5.6 times lower total cost of ownership when deploying language models. Fewer GPUs, servers, networking equipment, data center space and electricity would be required to serve the same workloads compared to A100-based hardware stacks lacking optimization.
In addition to performance enhancements, TensorRT-LLM makes popular models easily deployable out of the box. Pre-optimized versions of GPT-J, Llama, and other frameworks are included, removing the need for manual tuning. The software is integrated into Nvidia’s Triton inference serving system and NeMo model deployment toolkit to further simplify workflows.
Early access to the package is available now ahead of its full release in the coming weeks. If TensorRT-LLM lives up to the potential indicated in Nvidia’s benchmarks, it could give the company’s H100 and future Hopper-based systems a decisive advantage over competitors in accelerating development and adoption of transformative AI technologies. Reduced costs and greater efficiency could unlock new applications for language models across industries.
The company, which has risen to become one of the most significant players in the world of AI and has been actively investing in the sector, is poised to ship over half a million H100 chips this year. These chips are in high demand, with both companies and governments vying for them as they sell rapidly.




